
2005 Mitsubishi Endeavor Wiring Diagram Original
- Category : Diagram Original
- Post Date : January 27, 2026
2005 Mitsubishi Endeavor Wiring Diagram Original
Mitsubishi Endeavor Window Wiring Diagram
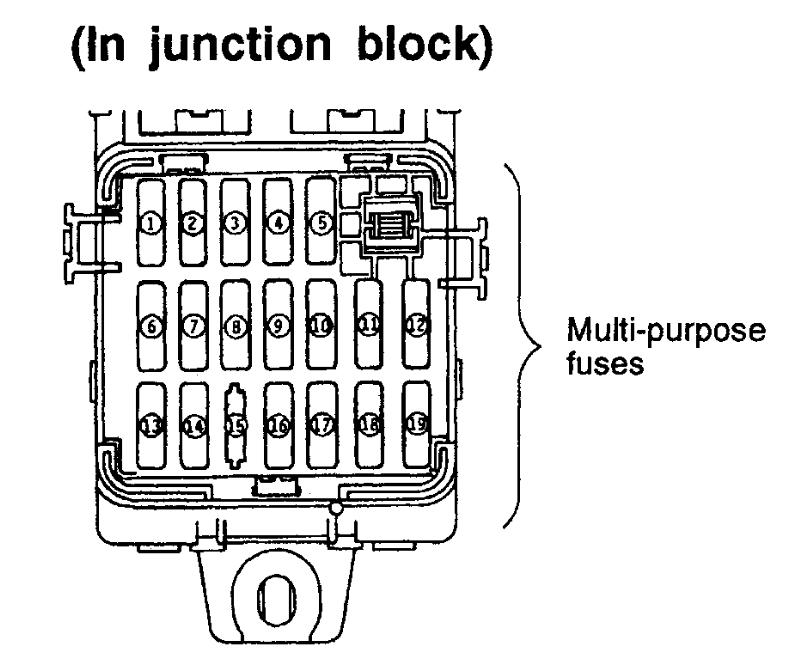
1998 Mitsubishi Eclipse Interior Fuse Box Diagram
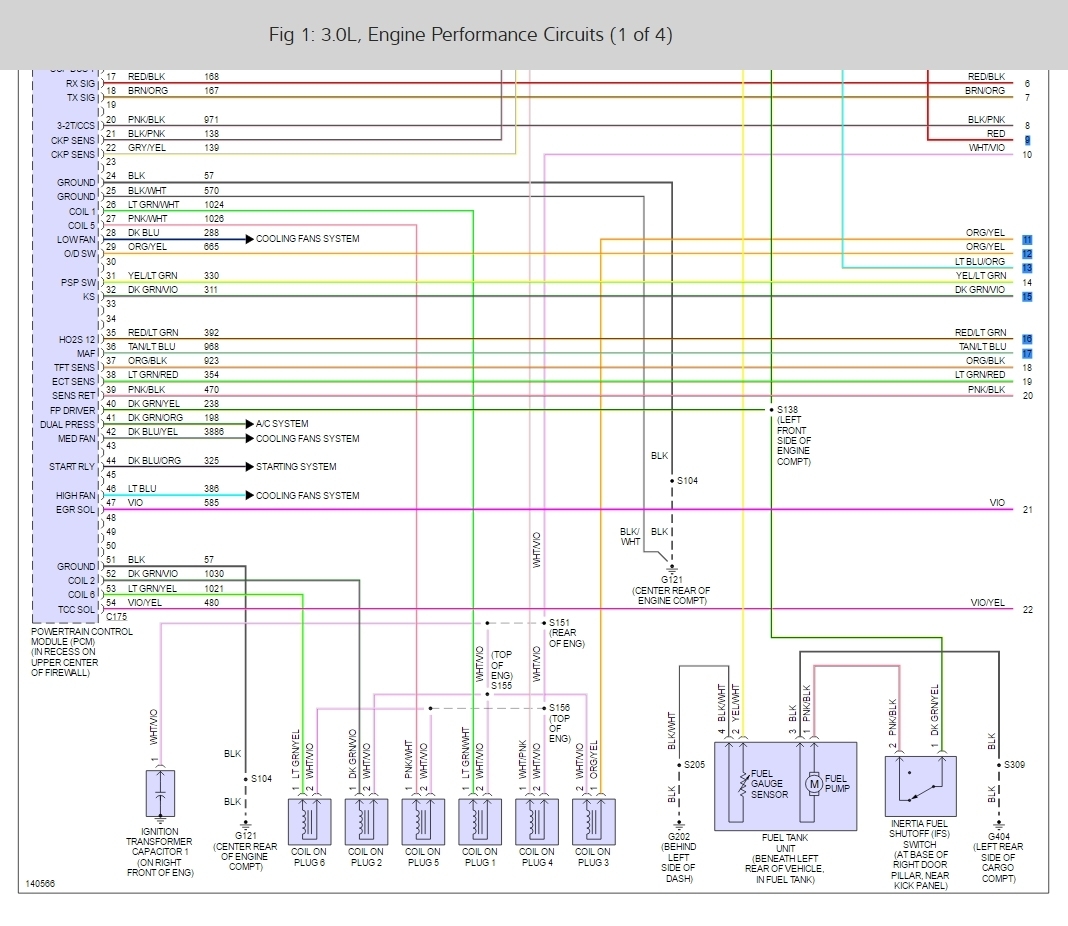
Pcm Pin Out Diagram Electrical Problem 6 Cyl Two Wheel

03 Galant Wiring Diagram

2007 Mitsubishi Outlander Wiring Diagram Manual Original
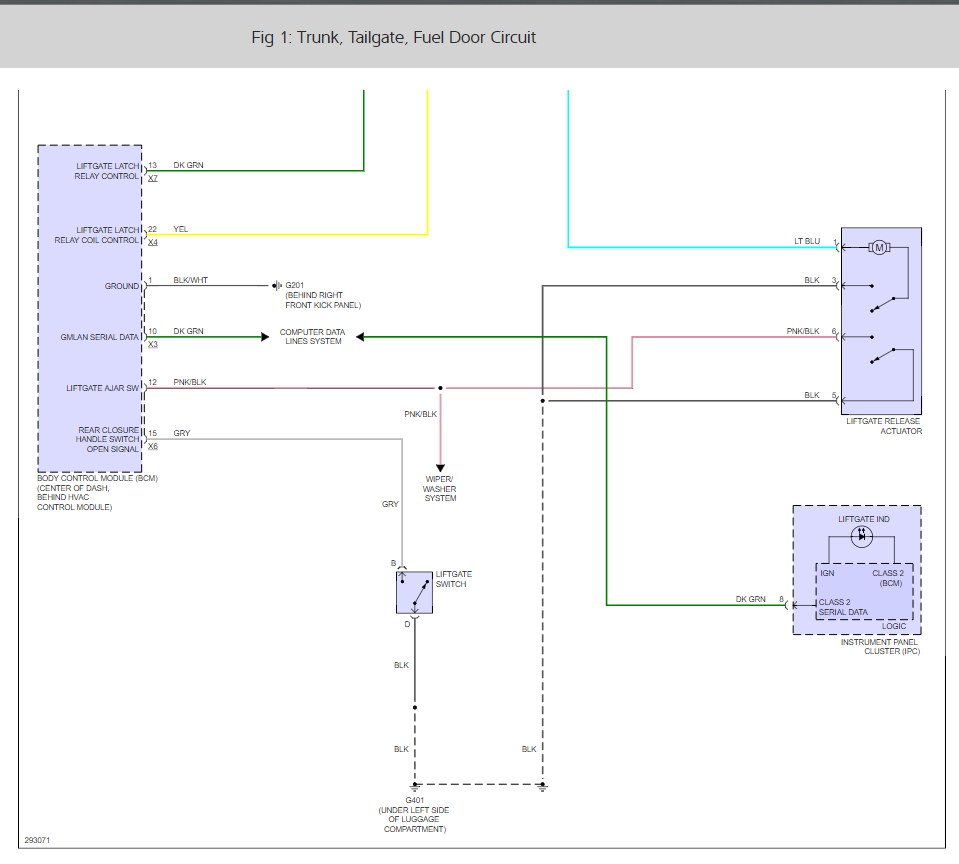
Rear Hatch Won U0026 39 T Open I Use The Emergency Little Door And

Fuse Diagrams For 1997 Eclipse
Diagram 2005 Mitsubishi Endeavor Wiring Diagram Original
Download 2005 Mitsubishi Endeavor Wiring Diagram Original
Stream Infer is a Python library designed for streaming inference in video processing applications, enabling the integration of various image algorithms for video structuring. It supports both real time and offline inference modes.
Experimental results on popular long text benchmarks show that Ltri LLM can achieve performance close to FA while maintaining efficient, streaming based inference.
When you invoke a SageMaker AI Inference endpoint with bidirectional streaming, your request travels through the three layer infrastructure in SageMaker AI:
Chatbots, search engines, and AI powered customer support apps are now expected to integrate streaming LLM (Large Language Model) responses. But how do you actually build one?
Learn how to deploy machine learning models for real time inference on streaming data using platforms like Kafka and Flink. Explore architecture patterns, implementation strategies, and real world use cases for low latency predictions.
Streaming of LLM inference is the method whereby partial results of the LLM output text start appearing to the user before the LLM has completely finished its query. This is a user friendly interface with a lower latency than waiting for the full answer before displaying.
Easy, fast, and cheap LLM serving for everyone. vLLM is a fast and easy to use library for LLM inference and serving. Originally developed in the Sky puting Lab at UC Berkeley, vLLM has evolved into a community driven project with contributions from both academia and industry. Where to get started with vLLM depends on the type of user.
Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine tuning.
Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence length without any fine tuning.
The September 2023 paper "Efficient Streaming Language Models with Attention Sinks" introduces StreamingLLM, a framework that enables Large Language Models (LLMs) trained with a finite attention window to generalise to infinite sequence lengths without fine tuning.
3 way switch,3 way switch wiring,3 way switch wiring diagram pdf,3 way wiring diagram,3way switch wiring diagram,4 prong dryer outlet wiring diagram,4 prong trailer wiring diagram,6 way trailer wiring diagram,7 pin trailer wiring diagram with brakes,7 pin wiring diagram,alternator wiring diagram,amp wiring diagram,automotive lighting,cable harness,chevrolet,diagram,dodge,doorbell wiring diagram,ecobee wiring diagram,electric motor,electrical connector,electrical wiring,electrical wiring diagram,ford,fuse,honeywell thermostat wiring diagram,ignition system,kenwood car stereo wiring diagram,light switch wiring diagram,lighting,motor wiring diagram,nest doorbell wiring diagram,nest hello wiring diagram,nest labs,nest thermostat,nest thermostat wiring diagram,phone connector,pin,pioneer wiring diagram,plug wiring diagram,pump,radio,radio wiring diagram,relay,relay wiring diagram,resistor,rj45 wiring diagram,schematic,semi-trailer truck,sensor,seven pin trailer wiring diagram,speaker wiring diagram,starter wiring diagram,stereo wiring diagram,stereophonic sound,strat wiring diagram,switch,switch wiring diagram,telecaster wiring diagram,thermostat wiring,thermostat wiring diagram,trailer brake controller,trailer plug wiring diagram,trailer wiring diagram,user guide,wire,wire diagram,wiring diagram,wiring diagram 3 way switch,wiring harness
